Leveraging Application Usage Data From Munki

Getting Application Usage Data at Scale With Munki
Munki is a series of tools and a popular application state management tool many Mac Admins across the globe use. Some out-of-box features of Munki solve problems many commercial MDMs still cannot solve to this day. It allows a Mac Admin to write some declarative data and have Munki takes care of the rest for you. We use it to manage and patch all of our third party apps in conjunction with AutoPKG.
Many projects or ideas start with a simple statement, or declaring what you want to accomplish. I feel this specific topic is one that requires this. I feel this is required, because I know many organizations will likely abuse application usage data for things it is not meant for.
One of the neat features of Munki, is that it can track application usage and Munki can take action from that data. You
can read about it here in the project’s wiki page. There
is a local SQLite database located in /Library/Managed Installs/application_usage.sqlite and it contains the data we
are looking to ingest at scale into Snowflake!
The schema for this db is:
|
|
So, you can just shell into that db on any Mac that has Munki installed and run some basic SQLite commands to look at what it collects. However, no one is going to shell into each individual end user computer and collect this data. It is worth mentioning that Munki Reports is another tool Mac Admins can use if they choose to, that can help centralize data and management of Munki.
When you work with data at scale centralizing your data though is extremely valuable for many reasons. Here are some top reasons why an organization would want to do this:
Data Governance:- implement RBAC controls on who can access what data, and protect crown jewels data
Analytics and Intelligence:- Build dashboards and data workflows to help automate and gain insights
Data Sharing:- Share your data across teams
Reduce noise:- Ability to join your data to multiple data sources and apply laser focus context to your data
I am sure folks have written books about this subject, so I will leave it with those 4 points.
Use FleetDM to Configure ATC in osquery
Osquery has a really neat feature called Automatic Table Creation (or ATC for short), and a good introductory blog post about it can be read here. It can essentially query something like a SQLite database and return the results into an osquery table. This is the perfect feature for a setup like ours. The first SQLite database I was targeting was of course, the Munki application usage database.
FleetDM does this a bit different from the Kolide blog post, but conceptually it is the same in the end. Let’s start with our requirements:
- FleetDM Stack
- Firehose Kinesis Stream to Snowflake
- A Munki deployment
FleetDM has the ability to modify the osquery config files per a team, this allowed me to set up ATC in a controlled and phased fashion. There are also some caveats, as I found out the hard way that if your YAML file in FleetDM is not quite in proper order osquery will skip over your decorators. See this issue for more details.
Decorators are important, especially if you ship osquery data from FleetDM downstream to a product like Snowflake. They are included in every query result, thus it is a smart idea to put unique strings or IDs as a decorator, so now you have a primary key in your data you can use to join to other data sets.
So, again please test everything out against a small subset of your systems and use a phased approach before you go all in on any osquery configuration change. Here is a sample of a YAML config you can use to accomplish ATC:
|
|
When working with data, you might want to do things like SELECT * FROM FOO_TABLE; and this might get the exact results you
want. This may work for a very long time as well. However, it is more of a best practice to be very specific in the tables
you select to avoid breakage downstream. If Munki were to add a new column to their database for any reason that SELECT *
would also include that new table. Now downstream any data models or preprocessing will have a new column to deal with
that isn’t defined. This could break things, and it is likely when it does break this is not the first thing you will think
to check. So, just start off by sanitizing your inputs, and only selecting the exact data you intend to get downstream.
In semi-structured data like JSON this is much less of a risk as you will likely just be missing a new key.
When you use ATC to create a table FleetDM won’t recognize it as a valid table, and you might see this warning message when trying to run a live query:
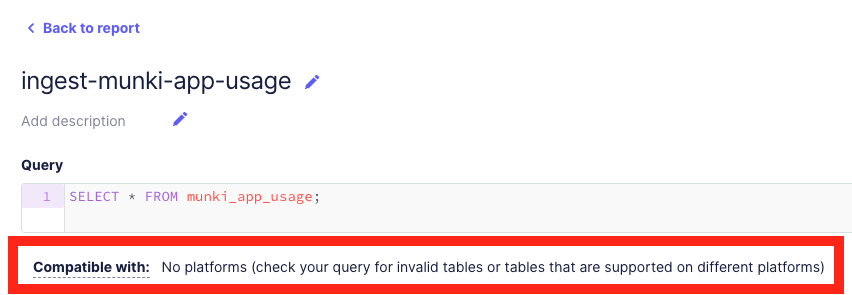
If you just ignore this message and YOLO it anyway and hit that query button, you will see you actually do get results:
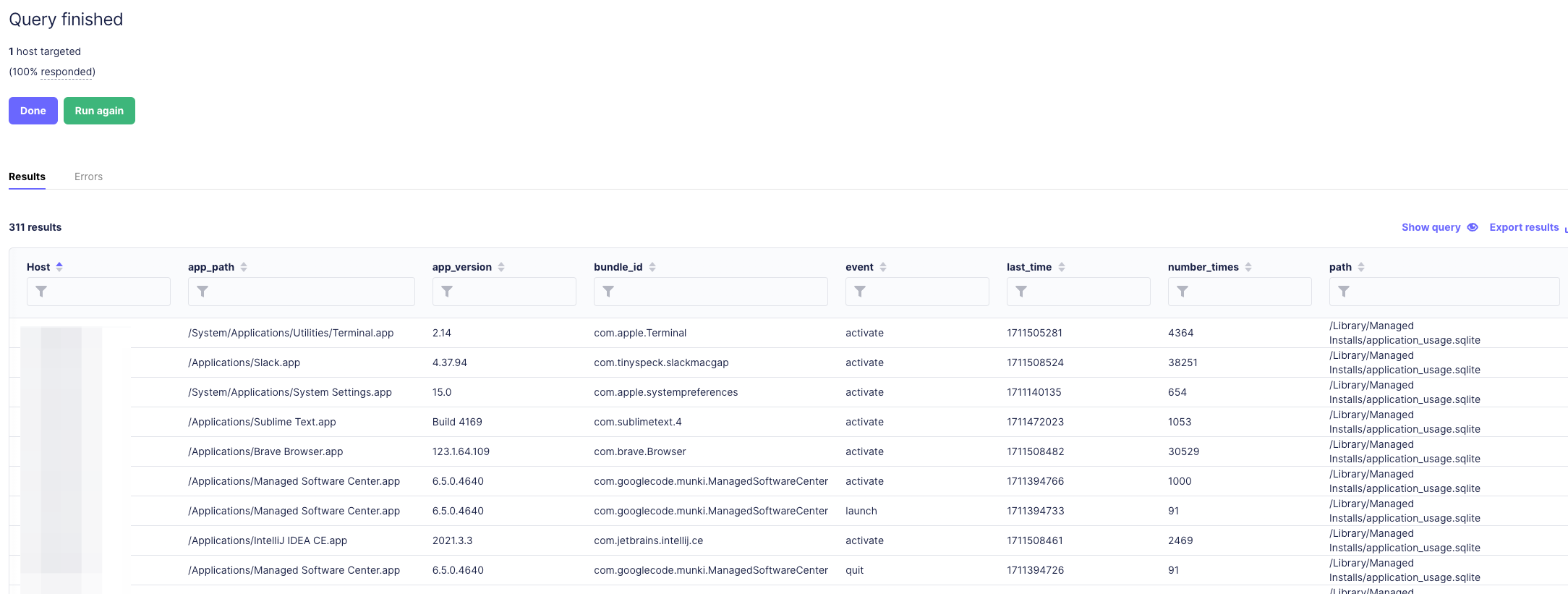
You might notice that there are several event types the Munki collects about an application. They are:
Activate- This monitors when the application is the foreground appQuit- This tracks when the application is quitLaunch- This tracks when an application is launchedNumber Times- The number of times each event has occurred in totalLast Time- Epoch time stamp of the last time this event occurred
This is actually great and exactly what most organizations need to monitor application usage, for its proper intended use. Which is license revocation and cost savings. Trying to monitor application usage for other use cases is a bit of a mixed bag at best, and awful at the worst.
Modeling the Data in Snowflake
For this and most of our other osquery data ingests from FleetDM we typically do a 1:1 data model. Meaning that we write a single query, that typically does a single purpose in FleetDM and ship the results as a snapshot in time to Snowflake. We worry about transforming the data downstream within Snowflake itself. This allows us to quickly get data pipelines going and then transform downstream when it is already in the product. Some of our JSON files can be over 20,000 lines of query results, and this sample I am going to share is about 700 lines of JSON.
An example of query results:
|
|
I’ve truncated the results above, but you might notice I just grabbed 2 events for the Slack.app. This shows the activate
event and the launch event. Now just imagine an entry like this for every application used on an end user’s device.
In a previous blog post I covered some data modeling in Snowflake with FleetDM data at a high level. We will still use those same high level concepts here. We can create a view by running the following SQL:
|
|
Our data is structured in a way that our decorators that we put in the FleetDM configs for osquery are always split out into their own columns from the raw JSON data, and some other commonly used keys we use. Like the query name as this is something we will filter for quite often. I am also keeping the schema intact from the original source, the SQLite database that Munki generates. This is really for data fidelity reasons, and if anyone ever has to reverse all the work I have done it just makes the most sense to copy the schema data types from the source in the model itself. So, I keep that 1:1 relationship not only with the query results, but the data types defined by the schema as well. Another big bonus of mimicking the schema from the source is that I can produce the same results from the base data model as I could locally use the SQLite shell on a macOS device running Munki.
Lets Test Drive the Data Model!
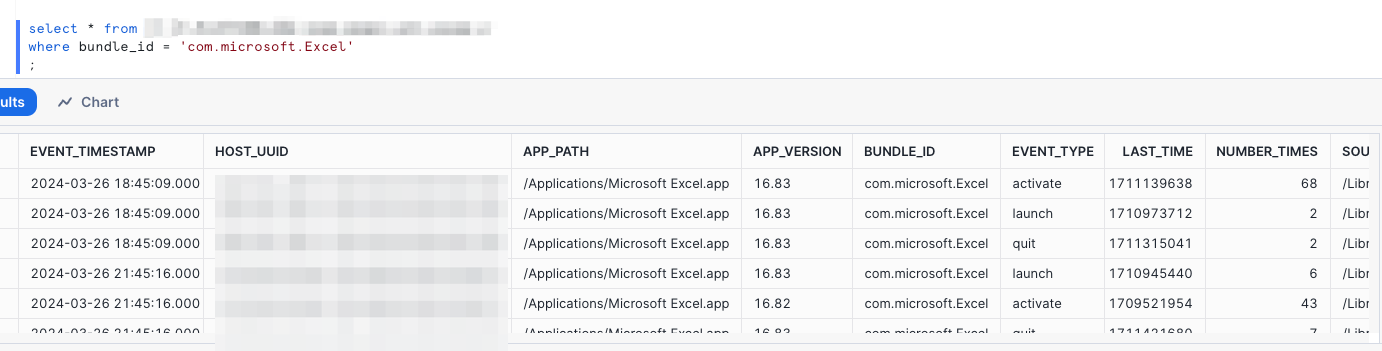
Now we just need to test our data model in Snowflake, and validate it is good to data share and use in dashboards and data applications. First lets just run a basic query against our data model and see what we get.
My favorite app in the world, Excel!
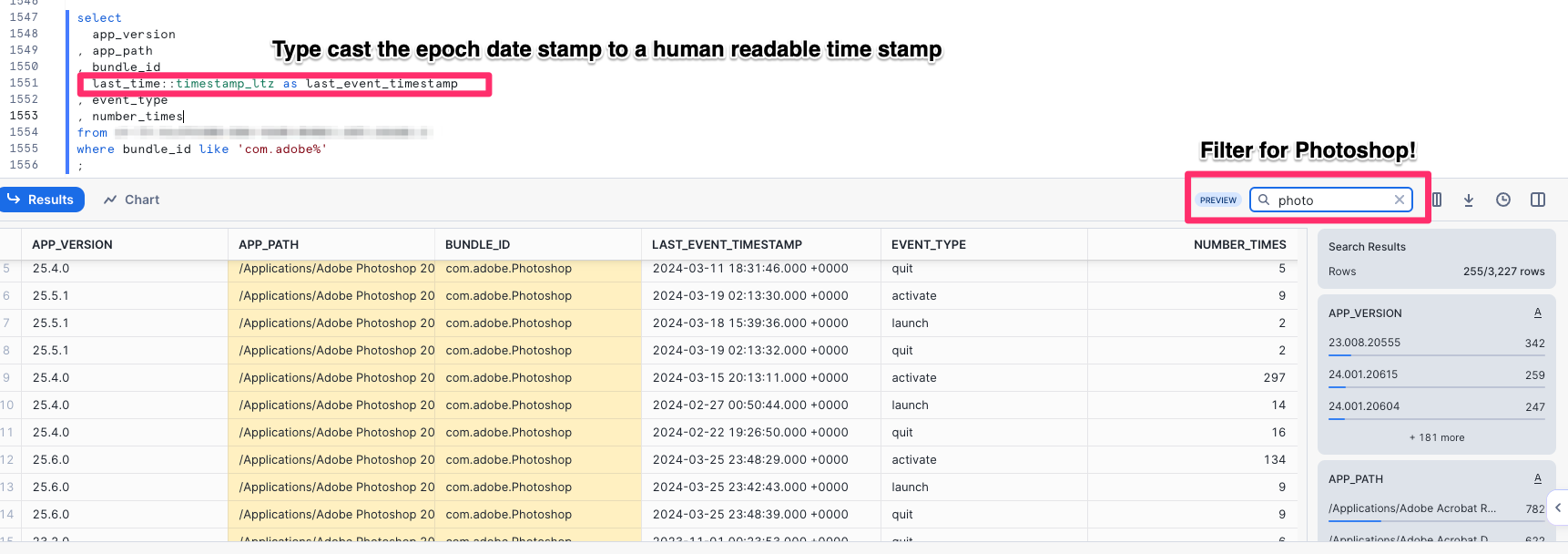
Now with a bit more filtering and more specific results for Photoshop!
Conclusion
Application usage data is a fanstatic way to track when expensive apps are getting used (or not getting used), track active license usage, help procurement with true up renewals, and just have a good general cost savings model. IT is sometimes viewed solely as an operational cost center, but now you can turn IT into a service providing cost savings by leverage good IT and automation tools and shipping your data to a platform like Snowflake. I bet we will use this model for true up renewals moving forward. This also is a good way for IT to capture what applications they likely need to offer in their self-service flows. If you have a substantial number of end users constantly using an app, perhaps this is an indicator it should be packaged up, deployed and patched/updated by IT.
There are many good use cases for this and those use cases can be tied to cost savings for the org and quality of life upgrades for your end users. Just remember application usage data is not meant to track productivity, or anything adjacent or even near that. You should not be shocked the majority of your users will spend the majority of their time in the web browser. I highly discourage any use of application usage tracking for anything other that quality of life improvements and cost savings initiatives (or things closely adjacent to these).