Complete Asset Oversight with the Data Cloud
Gain All the Insights You Never Had
Asset and Inventory controls are difficult, and many Orgs spend tons of time and effort to try to solve problems around this very subject. In fact, they will hire humans, and spend lots of time and money to also get a hold of their inventory of assets. This problem is still very much difficult to solve, but the Data Cloud makes this problem at least solvable. I have been in tech for over 20 years, and I have even had jobs where inventory of assets was one of my job duties. I had a local database I built on a Linux desktop and a barcode scanner where I could manage my own little shop of computers and computer parts. I would manually enter data, I would scan barcodes, and I even had a sign-out sheet for people to sign for things they took, so I could balance my books later on. Systems like this do not scale, they are very error-prone, and they take so much labor. Oftentimes I had to play asset detective and dig through our IT software, the home-grown database that I had, and the various paperwork from other systems to get a feel for what our inventory actually was. Also, I was very new to Linux and databases at the time, and I highly doubt my little pet project was really any good at all. It was at least something I suppose.
Times have changed since then, and that was back at my second IT job in the early 2000s when I didn’t have our current tech. We have made many advancements in technology and there have been many inventory and asset management suites out there, but there was one thing always missing from these tools. None of these tools have the ability to easily consume data form multiple data sources and allow IT professionals the ability to narrow in on their inventory and asset data. With the data cloud you can do this much easier today than ever before. While some asset and inventory systems do allow for integration, the amount of effort and labor is oftentimes very high and the return diminishing.
What once took many labor hours of integrating APIs, building manual reports in software interfaces, trying to work with other teams on centralizing data, sometimes having to email spreadsheets, and a plethora of other things most people did not enjoy doing can now often be solved by writing a single query in the data cloud. Snowflake has focused on making data pipelines easy to manage in the cloud and ensure they are coming in as often as you would like. You can now get all the data from all the sources and leverage them all to get the most complete data around your assets. Things like this haven’t ever really existed to my knowledge until recently.
Fix Data Upstream to Improve Quality of Data Downstream
I think it is a good idea to remind yourself, and your coworkers that everyone possesses the power to change things. If you don’t like something, you can put in effort to change it. If something is too complex, too labor-intensive, or just something in general that is not great, you can try to improve it. It just takes time, effort, and motivation to do so. If you don’t have great data around your assets in your downstream data warehouse, you can easily fix this by just adding that data into your asset software. If you have existing data pipelines and continuous data ingestion you should be able to add data to your CMDBs or whatever you use for inventory of assets, and that pipeline should pick it right up.
I know this works, because I have done it more than one time. A few quick examples of data I needed to get a better picture of our asset states were the following, but not limited to:
- Adding
Testeras an asset type. This means I could flag computers running beta software as testers and filter them accordingly Leave of Absencewe have a checkbox for this. Now if an employee takes a leave of absence, we can mark their asset with this- Adding
Demoas an asset type when employees that need to take computers on road shows, conference booths, and similar
These things actually impact numbers, and they can be filtered to meet your contextual needs. Sometimes we will see several points of a metric change by filtering these things out. Like for an example, you filter out tester and demo laptops from your workforce fleet, and it shows you a more accurate number of device compliance with devices that can access production systems. As well as filter out false positives when a computer running a beta version of macOS has a failed security agent on it. As your company grows these problems also scale right along with you. A 5% variance at 100 devices versus 10,000 devices are two very different numbers.
A Simple query example could be:
|
|
The three asset types I want to filter for in the above query are Primary, Secondary and Conference Room assets. Since we already spent time and effort in our Asset Management System, why not reap those benefits downstream in our data cloud platform? This query is counting all the assets by those three asset types and then giving me a grand total of all of them combined. Seems simple enough right?
Never Get Rid of Data, Just Filter It
Data with context is very useful, data without context is not very useful. When you are able to ship all of your Inventory and Asset Data, your IT tools data, your security tools data, your HR data, and so on and so forth you can now leverage all of it to get precise contextual data. So, my philosophy is to never get rid of data, but instead filter it in specific buckets with the proper context. In a previous blog post I wrote about our first Nudge campaign, and it is a prime example of filtering, but still keeping all data. I will reuse my Nudge data to show a quick example of filtering.
Observe this filtered data in the figure below:
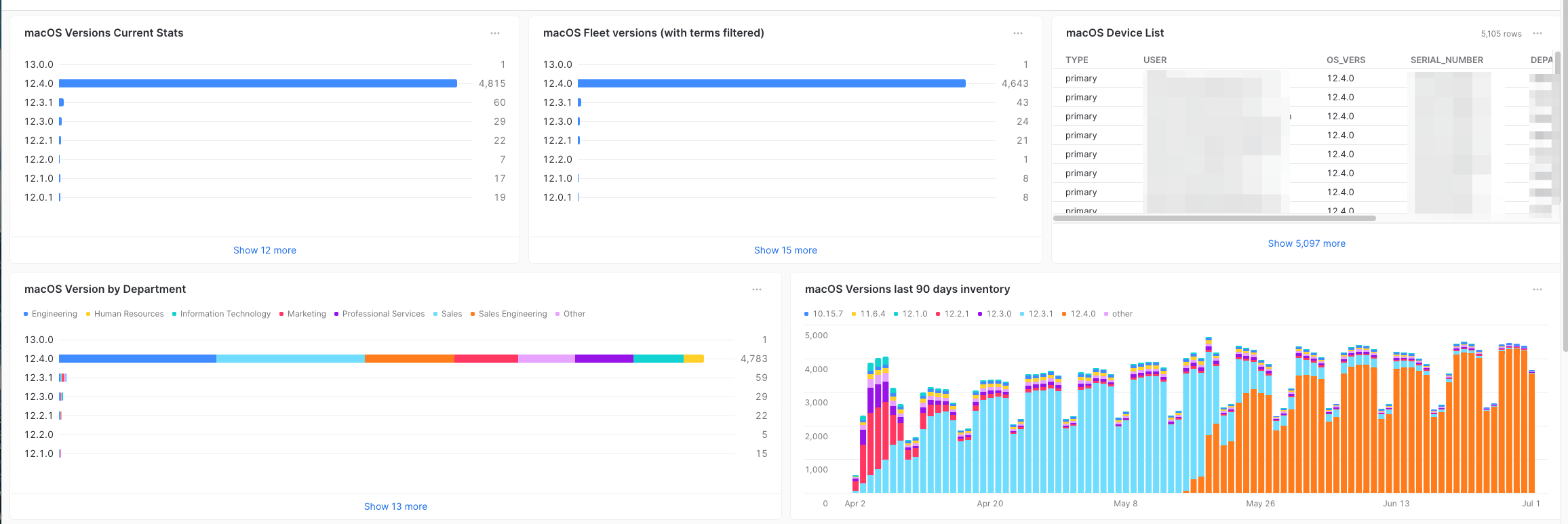
Every Org has employees on-boarding and off-boarding every week. The larger the Org the higher the number typically. I even worked at some Orgs that were so large we would see 25,000+ people join the company in a single month, and we could have somewhere in the ballpark of a similar amount of folks leaving. In the above screenshot I can now compare my asset data in the current state, but also apply HR data to it to see if folks are exiting the company. Assuming your Org has a process for exiting employees and that the asset is taken and securely stored for some sort of hold period that data may not be in the most current state as it typically involves humans interacting with other humans and manual data entry. This is why we always want the keep the all the data and apply context. You will notice just filtering out leaving employees the numbers are different. Another reason you keep the data is that Security Teams may want to track exiting employee systems for security events.
Inventory and Asset Data is Security Data
Security is always a high concern with organizations, and inventory and asset data are in fact also security data. Having an actual grasp of your fleet is step one in understanding your attack surfaces and threat models. If you don’t know how many primary laptops are in your fleet can you accurately plan for securing them at scale? If you are not aware of how many secondary computers are out there how can you accurately assess risks with devices that may not be online to be patched? A secondary computer is likely to not be online every day, and only used when the secondary use case is needed. Out of all those systems you have at your Org, how many of the security agents are working on them? Does your IT and Security staff just install an agent and hope it works? Does your IT staff just write some scripts and call it a day? I hope not, and I once thought this was a near impossible task at previous jobs. I have always been fond of security and try to be security conscious when designing my systems. This has paid off, because now I base my health checks off of data in the data cloud. Before at previous jobs I would write a script, and maybe collect some metadata on the agents to see if they were running. These checks can catch some failures, but they also miss out on catching many other failures. Without diving-down a rabbit hole of edge cases, I can just point out that a security agent on an asset can be running, can have a process ID, can be taking up compute, but that does not mean it is submitting data to that agent’s cloud tenant.
Both Security and IT teams can now leverage all the hard labor and efforts folks put into managing assets at your Org. This data is not just useful, it is fundamental for all data queries we run to get exact context of our fleet.
Example query:
|
|
Visual Example:
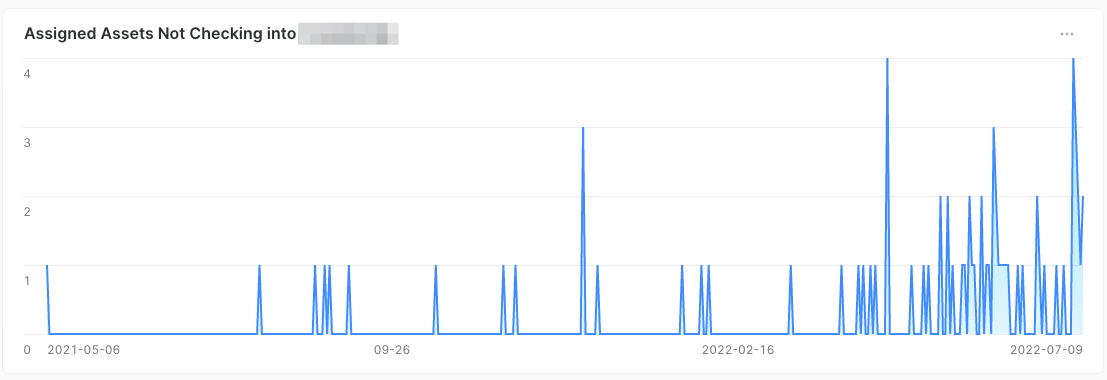
Now all teams are able to leverage asset data in their queries and treat our asset management data as a source of truth for all asset states Org wide. You just need to join this data in the data cloud. This is why asset inventory data is fundamental to many teams at any organization that wants to go down the data enabled path. It is a baseline for almost any data you wish to know. The above query takes all the assets we wish to see the status of and join it to security data, MDM data, and HR data to give us very accurate data sets of how healthy our security agents are. Security software cannot do this alone, as it does not have any knowledge of your asset data. If there is an integration that exists, you must build it and hope it works for your needs. With the data cloud you just ship the raw data and figure the rest out in post.
So many teams benefit from a good set of asset data in your data warehouse. The query above is letting us know every time
an asset hasn’t submitted data to the security agent’s cloud tenant in over 14 days. These queries are also very reusable,
and other teams can just simply modify that like dateadd() line for it to be any threshold in days from the current
date stamp.
Use Inventory and Asset Data to Fix Inventory and Asset Data
How do you know you are capturing all your assets properly? How can you tell what is an Org-owned asset versus a BYOD asset? How can you catch process failures and get proper data in your asset tracking system that is accurate? Well, when you ship all your data from all of your tech stacks to a data cloud platform this is not difficult to manage. You just join your data sources and delta the things that do not match! That is it, it isn’t some complex algorithm involving tons of API code, middleware servers, complex data tool designed for specific niche purposes, etc.
Query example:
|
|
The query above simply selects the absolute latest webhook data from our MDM service, meaning a device is enrolled into our MDM and sending events. So, a device must be actively enrolled into our MDM to get required settings and software to access Org owned systems and services at most organizations. This is a very common strategy IT leverages. However, how do you catch failures in your processes and automation? Well if a device is sending MDM events and not in our Asset Management Software, I would very much like to know about it. Maybe some manager uses the Org credit card and heads to Best Buy bypassing procurement and all of a sudden you have a dozen rogue systems in your MDM with zero of them in your Asset Manager. The above query captures this and gives you all the info you need to go create a record in your Asset Management Software. This is also a good way to track BYOD systems, as a BYOD system is never procured internally, nor is it Org owned. All of your incoming agent data can be used to find all the missing systems that have fallen through the gaps.
I think we can all admit that not every computer hardware vendor offers the same level of service and integration when you buy assets from them. Some of them can get that data fully automated to your asset software, and other vendors can at best email you a spreadsheet of devices. Also, mistakes happen, and what serial numbers of devices are on your paperwork versus what you physically can be different. We can use all of our external systems’ data sources to fix and clean up our asset data.
I do not know of any Asset Management Software that can do any of this, and if some can I would be very interested to know
if it is this easy to get that sort of data and insights with their software. This is why asset data is so fundamental to
every Org out there. When I started my data journey a few years ago I would have laughed if someone told me all I needed to
do to get this data was to use not exists in a single query with a few joins! I would have not believed it.
Things to Ponder
If you are struggling with getting control over your inventory of assets at your organization, consider using something
like a data cloud platform to leverage your asset data along with many other data sources. If you truly want your
asset software to be your source of truth of what physical assets are assigned to what humans at your organization you will
have to put in a lot of effort to maintain this and ensure its accuracy. In doing so, you can also ship all that data and
benefit from your labors exponentially across your entire organization. Data Sharing makes this possible, and I feel like
I am not stressing this enough, Data Sharing is the future. Legacy systems cannot accomplish this as easily, and they cannot
scale like the cloud can. I could probably write a short book on this subject alone as asset data is so useful across
so many queries for so many use cases. This is why I keep calling it fundamental as it is the baseline of all your
metrics and asset data.
Then you can use all the data to literally improve your asset data as well! It is really hard to gauge the value a platform like Snowflake brings to IT and Security teams because it is exponential, quantified by scientific notation, and one single piece of data can be reused in countless queries, metrics, intelligence and more. Making your returns on the total cost of ownership of the data cloud nothing short of fanstatic. We use this data along with other data sources to improve our asset data all the time.
Remember failures happen, even Amazon, Google and Microsoft cannot guarantee 100% uptime, and they have more money and resources than all other Orgs on this planet! The data can be rough at times, and it can give ya a good old-fashioned gut punch when it doesn’t look good. This is something you must accept when becoming a data enabled organization. However, it gives you a path forward to fix things always. Without this data you just wouldn’t know you had these problems, you had these failures, and worst of all no data to help you with a path forward. You can only fix what you know you need to fix, and the data cloud helps organizations in many ways. Wouldn’t you rather know these things?