Diversifying Your IT Tools: Integrating Munki
Hello Everyone, and it has been a while since my last blog post. I have been busy with work and with some other things
outside of work as well. However, we did finally release Munki to our fleet last summer. This was a milestone project for us, and
while we aren’t the first Org to do this, I wanted to share with the community how and why we did this. Everything I will
write here has probably already been done by many other Orgs that currently use Munki, and we aren’t really doing much
that is radically different. So, if you hae deployed a server-less Munki setup before, this is probably not going to be
new to you. That being said, server-less is a pretty key word for our vision here.
How it all started
Over the years I have been privileged enough to peek behind many curtains around the globe when I worked as a professional services engineer in vendor space. This has given me a lot of perspective on how many different IT shops, all try to solve very similar problems. One of those common problems is patching third party applications. We all know vulnerabilities just keep coming and never stop, therefore an endless amount of patches and updates for apps also come out as well. When I swapped over to my current job in 2019 I built this as our solution. It leveraged autoPKG and another tool JSS Importer which is now sunset. Jamf is also changing their classic APIs which will break JSS Importer. With these changes on the horizon we had to make a decision, to either migrate everything to a new integration like jamf upload or look at using a new tool. One thing was definitely certain and that was that we would not be manually packaging up and deploying software updates. It had to be automated, no other options allowed.
Building the Requirements
When you sit down to design any system at all, it is always a good idea to start with a best-case-scenario. List the things you want to accomplish, and list the things you want to avoid. I have found that as my tech career has advanced I have observed many things that don’t work or scale. I have also done many things myself that don’t work or scale. This is fine, normal, and acceptable. Many times you will not know what to do or how to scale unless you start somewhere. Start trying things out and see what results you get. Trial and error is a part of the scientific process after all. Always bring your experiences with you, but also keep an open mind. Here are the things I came up with before I even looked at choosing the proper tools, or path we were going to take.
- Has to be server-less (content delivery model)
- Everything has to be in version control
- We need CI/CD
- Everything needs to be in code
- All development should be done locally
- Our dev environment should be the same for both local and CI/CD environments
- Any Mac should easily become the build server if need be
- Everything needs peer review
- Avoid large efforts in API integration
- The tools should do a lot of the basic work for us (versus us writing tons of scripts)
- Easily able to integrate this into any MDM
Socializing the Requirements
Why server-less? In previous jobs I have been a Linux/Server administrator. This meant I had to deal with vulnerability scans, patching, downtime, upgrades, monitoring, on-call rotations, and all the other things that no one really likes to deal with when it comes to server and on prem infrastructure. So, then to solve this problem, I just get rid of the servers. You cannot vuln scan or patch a S3 bucket or CloundFront CDN that is hosting your software packages. I wanted to just go to a content delivery system and serve up content on a CDN and have the client just fetch it when it needed to. I based this off experiences across many past jobs where I had these extra responsibilities of managing all of our server infrastructure.
I wanted to shift us into an engineering focused and automation first approach, over some legacy IT Operations processes that are out there. So, I socialized these ideas with my leadership and peers. I wanted to adopt more DevOps practices, and steer away from things like manual QA or manual paper work to move something like deploying an app or an app update through an end-to-end process. So, when we expanded our team I went after DevOps engineers and not Mac Admins. I wanted a more diverse set of skills and experiences to help build a modern team. Luckily for me, my boss agreed.
The Tools
This is what we ended up with after some discussions and a few tests:
- Munki
- AutoPKG
- AWS Hosted Mac Mini
- S3 buckets
- CloudFront CDN
- GitHub actions and remote runners
- Build tools
IT Development Cycle
Here is a rough diagram of the flow we started with. Things can change too, and we are open to change, but I think we have a solid starting place to base us from. (starts left to right)
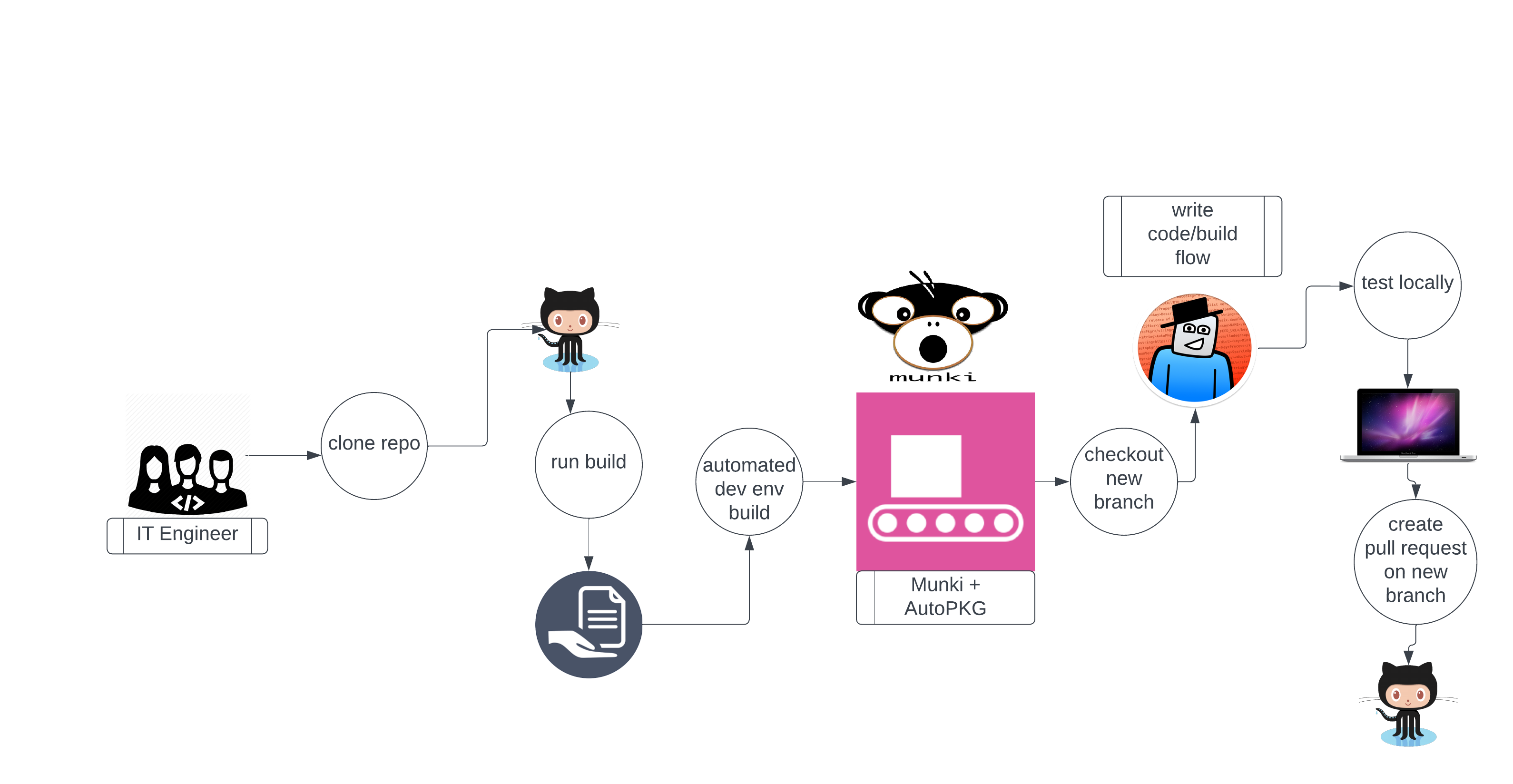
Essentially, one does the following to deploy a new app and have Munki automatically update it:
- Clone the Munki + AutoPKG repo
- Run build tools
- Build tools will build the full local environment
- IT Engineer checks out a new branch and builds the AutoPKG recipe and tests it locally to ensure it works
- Build tools can build a fully functional Munki environment locally using Python’s simple HTTP server and a local repo
- Commit and push changes to branch to the remote repo
- Create pull request
- Another engineer is required to check the branch out, test it, and approve/deny the pull request
- Approved pull requests are merged back to the main development branch
- downstream we promote the main dev branch to stage, then later on stage to prod
This way any Mac can easily be a development environment, AutoPKG server, and local Munki test environment as well. AutoPKG
builds locally and outputs to a Munki repo in /Users/Shared which you can point your own Mac client to as well. Managed
Software Center should see your Application. There is a simple Python build script our DevOps engineers wrote that runs the
whole test end to end for a full test. This is the exact same environment we run on the Mini in AWS, with one minor exception.
That minor difference is just that the Munki repo in /Users/Shared will get synchronized to S3 via S3 folder sync. This
is done through GitHub actions and remote runners on the AWS Mini. We also use branch promotion, which means engineers can
only ever commit and merge changes to the main development branch. The stage and prod branch do not allow for direct commits.
This allows us to force a peer review system and when we automate promotion from development to stage, our early adopter group
of end users gets the changes in stage first. Lastly, if no problems are reported or found, we then promote the stage
branch to production. This is mostly possible due to us using version control.
Why Not Just Use MDM?
MDM solves problems, but typically only for MDM things or in MDM specific ways. This means it is oftentimes binary, absolute, and lacks options. Also, the UX of MDM options are also not great. One major example is that MDM solutions will often just bulldoze over running apps to patch them, and this is not a good UX, and could also result in data loss. I already had dealt with JSS Importer + AutoPKG + Jamf Pro, and it was a lot of engineering efforts for me to maintain. I also had to have a series of scripts and smart groups with in Jamf Pro to have the proper automation and UX I wanted to provide. Munki allowed me to retire all my API integration, all my bolted on top of the product Python code, and reduce my team’s actual labor by not having to deal with click-ops.
MDM also has no real concept of version control, or anything meaningful in that space. It is a highly requested feature that has been around for many years and no MDM vendor really adopted anything around a version control system. If I wanted to enforce peer review, and build a decent and scalable testing process, version control was going to be a hard requirement for this. MDM solutions do offer up an API, but in my experience it typically requires lots of work and effort to build and maintain forever. Also, many MDMs are not API first, nor do they offer every an API endpoint for every feature in their app.
Munki for us is server-less (no servers to patch), can be integrated into any MDM we purchase, leverages version control, reduced our labor exponentially, modernized our tech stack, CI/CD, and the out-of-the-box features allowed me to retire half a dozen Python scripts. So, we still very much want to use MDM, but the way we built Munki, we can take this with us if we ever decide to swap MDMs.
Avoiding Vendor Lock-in
Another pitfall I have both personally done, and witnessed many times in my career, is that avoiding diversifying your tools stack can put you in a bad position. Let’s say an event happens, like a very bad event. A data breach can easily scare your leadership into making you get rid of the tools that suffered the data breach. Commercial MDM tools are a big risk here of vendor lock-in, in my personal opinion, especially if you bolt tons of custom development on top of them. I get that an IT Org probably has their MDM in production, and it has been approved through all security processes. Painful security and procurement processes can deter IT teams from wanting to deploy multiple tools, and this can put you on a path to vendor lock yourself with a MDM. The way MDM is designed in its current state, it naturally puts you into a vendor lock situation.
Changing MDMs is very painful with Apple products. Apple has never really built any migration paths, and they leave it up to the MDM vendor to build these. Well, what incentives do commercial MDM vendors have, to write code and features around off-boarding a customer to a competitor? I guess this was Apple’s idea (not sure what their idea is)? Basically, it isn’t going to happen because no commercial MDM vendor is going to spend dev cycles building a tool to help you migrate to one of their competitors. So, with a tool like Munki, that is completely separate from MDM, can slipstream into any MDM we choose. My team can suffer slightly less if we have to migrate to a new MDM. We also don’t have years of tech debt and custom dev piled on top of our MDM that makes migrating even more difficult.
So, imagine if you build entire middleware systems of integration into your MDM, and the MDM ends up being not the best tool for your organization? What do you do? Do you suffer with the current MDM and the massive amount of tech debt, or do you decide to take the 2 years it will take to migrate to a new MDM? I have both worked in these environments, and observed these environments. From my experiences and hard lessons learned, I think diversifying your tools is the smart and agile thing any IT shop can do. It also positions the business/Organization in a much better place allowing for negotiation and migration of newer software tools in the future, if applicable.
Tools to Explore
Here goes some tools we use, or are in the process of using, that are independent of MDM. We can swap out each tool independently, for another tool in that space and we don’t have to tear our entire stack down. This approach allows my team to be modular and agile. It also allows my Organization some flexibility other Organizations may not have, because we can take specific tools out and replace them with other like tools. There is also feature overlap, so in a bad situation of having to sunset a tool, we will have at the very least, some coverage of features while we integrate the new tool.
- osquery Cross platform data collection, improved data collection
- GitHub Enterprise Version control, CI/CD via GitHub Actions
- Nudge Notification tool to notify end userse to upgrade macOS (huge fan of this tool)
- Gorilla Application state management and deployment tool for Windows that is similar to Munki
- Munki Application state management and deployment tool