Working with osquery Data in Snowflake
I recently told my dog, Booms, all about how you can use osquery data in Snowflake. Needless to say, he was quite impressed with all the use cases and in-depth data you can model about your fleet of laptops using osquery data in Snowflake.

Booms came to the office with me, and he even got a bit of company swag! As we spent the day working I told him all about all the work my team was doing with osquery. Anyone can see in this pic of him, he is very impressed with the speed and scale one can leverage data from osquery in Snowflake
Quick Recap
A while ago I posted a blog about osquery, FleetDM, and Snowflake. You can find my old blog post, here We are now using this tech stack even more today, and while we have been working on many other different projects we have made progress with our osquery story. If you are unfamiliar with FleetDM, osquery or Snowflake I suggest you read the previous blog post. The basics are covered there.
Our setup is FleetDM managing osquery, integrated with Snowflake. Leveraging AWS cloud technologies like S3 storage, and Kinesis Firehose to stream data in near-real-time. With Snowflake’s Snow Pipe to rapidly ingest data, so we can get data as fast as we choose to.
Some Problem Statements
People may be curious as to why we want to deploy more tools to collect data, when there are things like MDM that most IT Operations shops already have. The simple answer is that osquery is just way better at collecting data, it is cross-platform, and it gives us much better control over our data pipelines. So, here are some things we are initially trying to solve:
- Proactive monitoring
- Performance monitoring
- Security and Compliance data
- Extended software gathering
- Bridging gaps in current data collection features our or tech stack
We have many more use cases, but we will continue with the above. One of the problems IT has always faced, is the ability to predict when a device is going to have problems and proactively help or fix/replace an end user device. Security will want all the sweet data that osquery can provide, you just have to inform them you are able to leverage osquery, and they will have asks.
Performance data is tough to track on end user devices. Unlike server infrastructure, end users can do, well anything they desire to do. Like run tons of apps, configure their technology how they see fit, and develop workflows that you have zero insights to. Your end user’s workflows may be very foreign to you as well. IT folks may have no idea what a marketing or sales staff may do. Professional services folks are a great x-factor to mention as well. They do all sorts of things customers ask them to do. So, tracking an end user device’s performance can be a great way to tell if you are over/under spec’ing the device, or if certain applications on the device are potentially not optimally configured, etc. However, none of this should stop you from trying to understand what your coworkers do day to day, and how you could potentially help with data.

Booms felt skeptical that we could pull this off at scale. I told him we would never know if we didn’t try
A Decent Start
Before I dive into what we have done, and how we have leveraged the data, I would like to mention that we have not turned on any events based tables in osquery yet. So, the performance data we have is a snapshot in time, of the most expensive compute processes since boot time. The caveat with this data is that it doesn’t tell us how long these processes ran. If a process runs at 900% cpu usage from a 10core CPU system for 5 seconds, is likely a different story than a process running at 500% CPU usage for 25 minutes on that same system. As well as a process taking up 5 cores on a 6 CPU core system, versus 5 cores on a 10 CPU core system. While we do not have the full on events’ data yet in osquery, we do have something to start with.
Event tables in osquery are a bigger compute cost to leverage. We plan on exploring these tables, but we take UX of our laptops as a high priority. So, the enabling of the events’ data in osquery will be a slow roll-out while we monitor any potential impacts we could potentially encounter. I would also like to point out, tons and tons of effort has gone into making osquery much more performant over the years. So, if you have not tried a modern version of osquery I would recommend that you give it another go!
Let’s look at some data!
Consider this query in osquery:
|
|
The above query cross joins the processes table and the cpu_info table
to get some basic CPU usage and context of the CPU data. I found this query from a blog found here.
I also found that blog post pretty informative around some performance monitoring concepts with osquery. So, we loaded this
query up in FleetDM and let it run to see what we got back.
|
|
When you automate a query in FleetDM, it puts the query in the Global Query Pack, and it uses the name of the query in FleetDM as the name of the query locally on the client. In the future I might dive deeper into the architecture, but for now I want to mention the query name as we will use this for a data model in Snowflake. Automated queries in FleetDM can be setup to stream to cloud storage, like S3 over AWS Kinesis Firehose, and the results are stored in JSON files like the example above. Snowflake can natively parse semi structured data, which is referred to as variant data
Furthermore, Snowflake has a feature called Flatten. Which is essentially a table function that allows you to “flatten” keys and values in a JSON file into columns and values. It is quite the handy and powerful feature for IT Ops folks as we deal with JSON data structures in so many things. So, one could apply some of these concepts with REST APIs and JSON returns that one could ingest into Snowflake as well.
|
|
- Since FleetDM streams query results to a single raw data table we are using
where raw:name::string = 'pack/Global/ingest-macos-top-20-processes'to filter the data for this specific query - Flatten was aliased as
fand we use simple built-in features to get the value of a key in the original JSON query results - Type casting each value is important, we probably don’t want the data view to use variant data types, but rather specific data types
- Remember this is snapshot data, not historical. These are CPU usage spikes we do not know how long the process ran for
- When data modeling, try to keep the view specific and avoid joining every data source into a single monolithic view
- When updating a view, you may want to use copy grants
Sample query from the view we created:
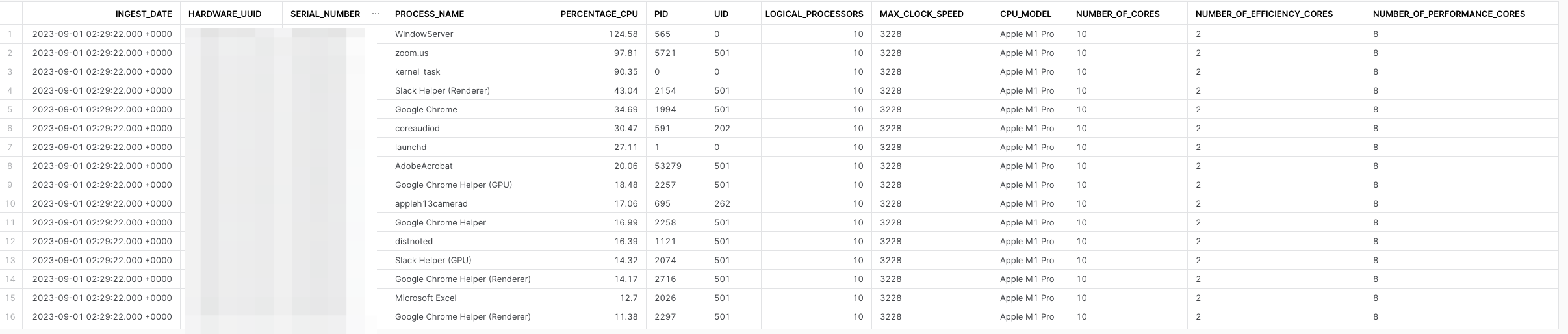
Let’s have some fun, what is the CPU spike for virtual machines across our fleet? Remember this is just most CPU intestine processes since boot, as we do not have events data to get a more accurate data sample. We are in the beginning of our data journey here.
|
|
NULL values, we just want to filter those out.The results:
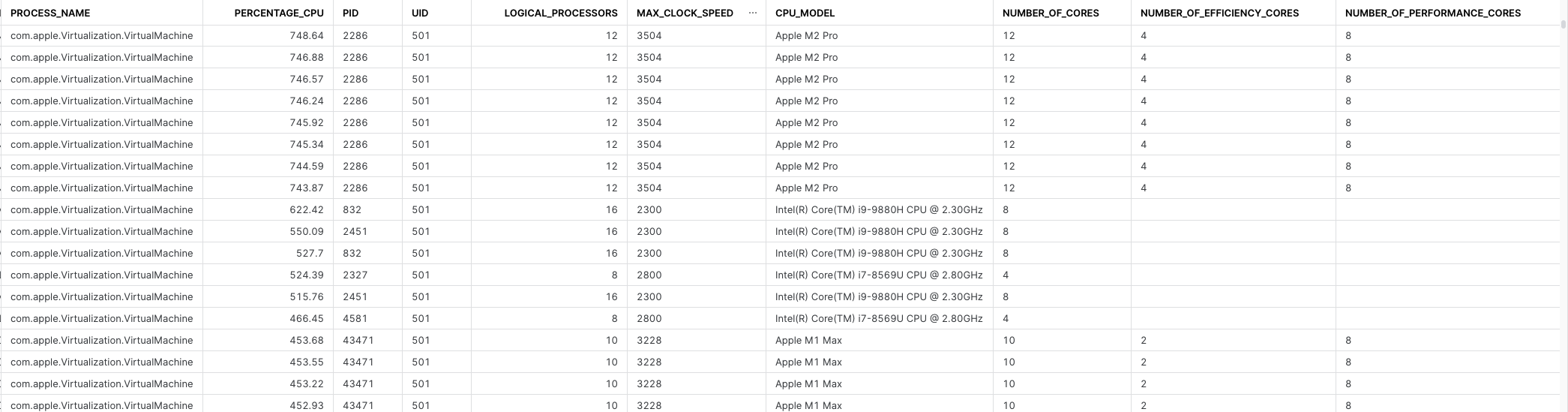
So, now we have some info around peak compute local VMs take across our fleet, what model of CPU and compute specs the device has, and we can also join this data to other data sources to enrich it. We could join asset data from ServiceNow and filter for assets actually in production use, we could also join it to HR data to apply what human is using this device, and of course we can join many other data sets in Snowflake to this.
Consider this osquery query:
|
|
A simple one liner in FleetDM will have osquery return the entire contents of the temperature_sensors table. That is
all we really need to do here, it is that simple. There are some osquery configurations we are adding via FleetDM as well,
most noteworthy is we are adding in the hardware serial number of the device as a decorator. This is simply to ensure the
serial number is in every query results and can be used as a primary key we
will use later downstream in Snowflake.
Yet another simple data model in Snowflake:
|
|
As well as some cool (or hot to toss in a dad joke there) data results in Snowflake!
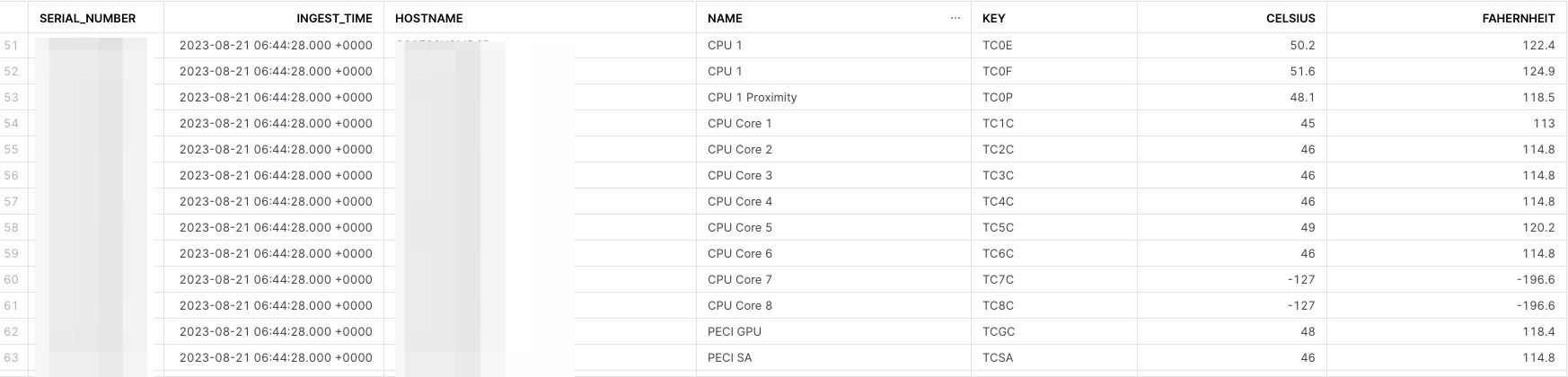
-127. I believe these to be a default value when a sensor
is not present or perhaps not functioning. I have not fact-checked this yet, but I know from my experience building gaming
PCs and constantly looking at temperature sensors, if you see a static value that looks off, that is oftentimes a default
value when a sensor is either not hooked up or missing, or not functioning.Searching Apple’s website I did find this article which tells me I should operate my Mac with in a certain ambient temperature range, but I failed to find an article that stated what the acceptable internal temperatures should be. Typically, with gaming hardware, like a higher end GPU you don’t want temps going over 90 degrees Celsius, but that is x86 and PC hardware. So I am not advocating that to be the line you don’t want to cross. If anyone has a link to an official Apple document that states internal temperature thresholds I would love to know!
What we can do with this data is trend it over time, and establish a baseline. If we take several months of temperature sensor data, organize it by hardware type (make/model), user type (developer, pro services, sales, IT, etc), and trend average temperatures we can at least establish a baseline. From there we can create alerts or automated ticket creation in ServiceNow to proactively reach out to users if we detect spikes in their internal temperature of their laptop. We should be able to determine that the average IT worker using a M1 CPU operates in this temperature threshold, and use that for a baseline of acceptable temperatures for all IT workers that have that same model.
Closing thoughts
We have more data coming in I did not cover yet. Things like browser extensions, application versions, systems data, how much memory is being consumed by what process, and more. We aren’t as tenured as some Orgs with osquery, but better late than never as they say! This is the beginning of this journey, and I would bet more blog posts will come from this.
If you got this far, thanks for reading! Here is a bonus pic of Booms when we took him to see some mountains along the Pacific Ocean.
