More Osquery Data Modeling in Snowflake
Data Modeling osquery Data in Snowflake
We have been working on many projects the past few months, and osquery data pipelines with the help of FleetDM has been one of our constant works in progress. Before I dive into the data modeling part, I wanted to share how we scaled this data out. We ended up going forward with FleetDM’s SaaS offering over self-hosting the app. However, we are still streaming query results from FleetDM cloud to Snowflake over AWS Kinesis Firehose and we now have data streaming from FleetDM into Snowflake at a very fast rate and high volume. We are typically collecting data from osquery every hour on most things, and we have a lesser number of queries that run every 12 hours or once a day.
Scaling the Data
When a query comes into Snowflake, it is just a JSON document with lots of keys and values, with some of those key value pairs being nested. Snowflake treats this as a variant data type and if you are familiar with working with dictionary data in say Python or Ruby this might click pretty quickly how one can simply parse native JSON in Snowflake.
|
|
In the above pseudocode is a very quick and dirty example of how one could get a value from a nested key using SQL in Snowflake. This assumes you have a column with just raw JSON data inside it. However, when you are streaming data from thousands of endpoints to cloud storage and then rapidly ingesting them into Snowflake you end up with many JSON files to parse. Parsing the JSON can be a much heavier compute process at scale. So the first thing I did was work with my data engineering team here and setup what is called key clustering
This pre-processes the JSON files as they come into Snowflake and separates specific keys into their own columns, and you can then model the data further after that. The big benefit of this is that you get all that indexing and caching features where you don’t really get that by parsing raw JSON variant data. So, we had already made some design decisions in our config files around this before, and we were now going to leverage those additions. We split up the following key/value data sets into their own columns from FleetDM osquery results:
- Serial number (unique identifier, can be used as primary key across many data sets)
- Hostname (not unique, but some tools only collect hostnames from other data ingests)
- Hardware UUID (unique and MDM tools collect this, so another primary key)
- Date stamp (we are going to be filtering by date ranges a bunch)
- Name (the query pack name, which again would be a very common filter)
The main idea here is that we were splitting out values of data that we knew we would use heavily for filtering and joining other data sources to it, and this helped us scale immensely. From our design decisions, we also added decorators for the serial number, hardware UUID, and the hostname. These are included in all query results. These can be useful primary keys to join to many other data sources in Snowflake downstream. Remember to always think about making data quality decisions upstream, so you can benefit from them downstream.
To give a quick summary of performance increase is I was querying 300 million rows of raw JSON data at first, and it would take 20 to 30 minutes to complete my query pre-setting up the key clustering. Post key clustering that same query could complete in around 30 seconds using the exact same compute. That is a pretty amazing increase and a vast UX improvement for anyone working with this data. So, if you go down the journey of streaming data to your Snowflake instance and want to really see performance increases definitely consider key clustering. Also, please talk to an expert on this subject. I am not an expert, but am lucky enough to work with a lot of experts on our data engineering team that works with us when we need their help.
Some Examples We Have Built
The osquery log stream from Fleet DM has 3 different data sets you can ingest. It has the query results, which is the bread and butter of the data, the audit log, and the osquery status. The audit log is just what you probably think it is, a full on change log of what is happening in the application itself. I have to hand it to FleetDM the log is very thorough, and it is one of the better ones I have personally seen. The last bit of data is the osquery status logs.
Audit Logs
|
|
The above data model is a real fantastic way to keep track of what actions users of FleetDM are performing and what objects in the application are being modified or accessed. This is the type of model you can hand off to your Threat Detection and Incident Response teams to monitor for anomalies.
|
|
The above query against the audit data model will show results of any person who has used the curl table in the
FleetDM product. This is really thorough, and if a bad actor were to gain access to an IT tool, they might try to
start using tools like curl to deploy malicious software across your fleet. Most IT/Ops tools I have personally
experienced in my career, do not have this level of auditing. Also, the power of Snowflake makes this such an easy query
to write. There are many actions you can track like, but not limited to:
- User’s logging in
- User’s being created
- User’s editing or executing queries
- Tables being accessed for live queries
- User’s fail to log in
- User’s role gets changed
- What the actual query code being ran is
So, this is really great for monitoring and auditing access, editing all objects in FleetDM, tracking who ran what live queries, and much more. Other vendors should really take note and build auditing trails this good.
Process Events Table
The es_process_events table contains process events from the EndpointSecurity API in macOS. This table requires additional configurations to be set in the YAML config file for osquery. This is a table that also can sometimes take up more compute if you get heavy-handed with it. You can use this table for lots of different reasons like but not limited to: What processes are running, tracking how long processes run, and extended metadata about processes that are running on your macOS endpoint. This can be very useful for both IT/Ops and Security Teams on what processes are running to later join to resource usage query results to get compute costs. Security teams can also use this for a plethora of security monitoring across your fleet.
This table is a bit “crunchy” to model in Snowflake due to the JSON data passing blank strings for things that should be
Null and also an integer data type. Here is a sample of one of my query results, which is actually a 19,908 line JSON doc.
Yes, each of the query results for each endpoint can be about 20,000 lines of JSON. This may seem like a lot, but it is really
not much in terms of what Snowflake can handle.
|
|
In the above example you can see a key for exit_code, which according to the schema and docs should be an integer, but in
the actual JSON results it is a blank string. This can be confusing and Snowflake has perfect ways to work around data
that is imperfect. I would expect this to return a Null and not a blank string of "" since the schema states this
should be an integer data type.
|
|
Keeping on with the example, lets look at this code: NULLIF(f.value['exit_code']::string, '')::number as exit_code and
break down why I had to do this. The JSON doc itself just passes a blank string since there was no exit code in this
set of query results. Trying to type cast a blank string to an integer doesn’t work, because there is nothing there.
So, I Null the data if no value is found by checking if it is blank (see NULLIF). In this case since exit code
has no value and the query results passed it as a blank string in the JSON doc, I am detecting if it is a blank string then
casting it as a Null data type if so. From there I can type cast it as a number (synonymous with integer in Snowflake)
if it is actually not blank. I definitely banged my head against my keyboard a bit on this one trying to figure it out
when I first encountered it.
So, when you are dealing with imperfect data remember that Snowflake has perfect solutions
Third Party Application Data
A very common data collection from osquery is the installed 3rd party apps on an end user device. This of course has many functions data wise. It is good for observing how fast you patch apps, what versions of apps are out in your fleet, what type of apps are users installing (helps understand their needs), and then the big one, collecting all the out of date and vulnerable versions of apps. Patch quickly, Patch often is a phrase you hear nowadays, and it is due to the amount of vulnerabilities dev shops are finding. With the help of bug bounty programs some efforts are also now crowd-sourced to the public. Thus, you can patch a single app multiple times in a month to fix known security issues.
Model code:
|
|
This is a pretty standard data model and nothing really out of the ordinary with it. I am using one of my favorite features
of Snowflake, which is flatten
and I use this feature so much. When we set up key clustering on our data ingest, we also put the snapshot key into its own
column. This contains the actual query results and is a series of nested data sets under the snapshot key. This makes
parsing dictionary-like-data easy-peasy. For context, the snapshot column is still variant data, and it is the remaining
JSON of the query results. So, when you are modeling data during your ingest process to add things like key clustering, you
can still just dump parts of the JSON file into its own column.
This is the output of select * from apps; in osquery, so we have basically a giant historical data set of every item
in the osquery apps table. This is very useful for many reasons, but really trending the data over time to observe how often
certain apps patch or do not patch, how quickly they patch, what apps are constantly showing up but not in your automation pipeline
yet? There are also some findings in here for security for things like a PUP
for example. It also can tell you how often apps are opened. This is super useful for tracking usage of licensed software.
If you have licensed software that can cost $100s of dollars or more, and it is not being actively used, and historically not used,
you can now trend that data to provide tons of cost savings for the organization.
Consider this query:
|
|
I am now using my other favorite feature of Snowflake, the qualify window function filter. This will return the latest data and only the latest data per an app per each serial number of devices in your fleet. This query was a bigger one, and it took about 1 minute to run and returned over half a million rows of data. I don’t find it shocking and in fact I would have sort of assumed we would have closer to a million unique apps across the fleet, but we are big SaaS users, so it tracks.
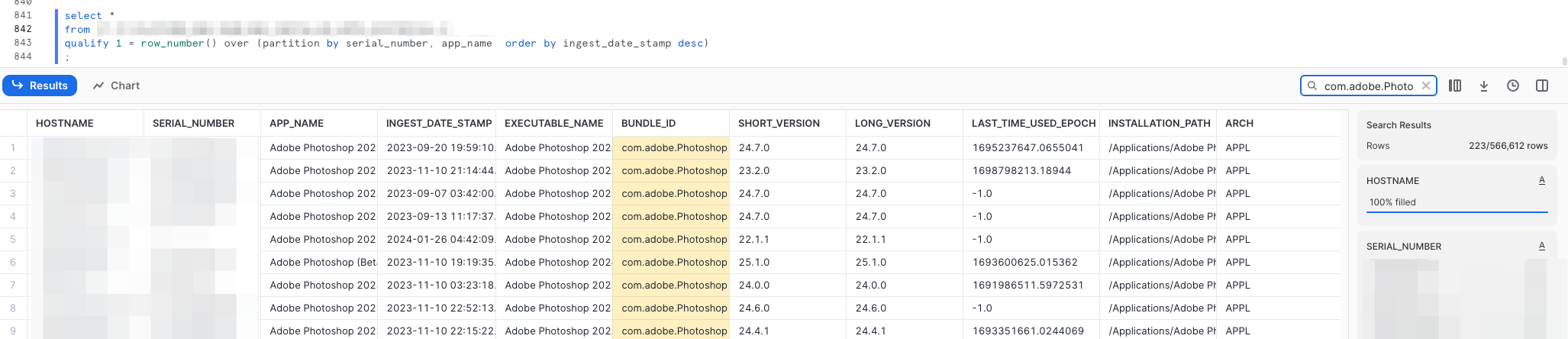
I took the opportunity to look at an app we all know and love, Adobe Photoshop. As you can see from the screenshot above we are able to get the last used timestamp and can do all sorts of things with that. If we issue an expensive app like Photoshop to someone who ends up not needing it, we can reclaim that license for another user that does need one. We always want to enable humans to do their best work with the best technology we have here. However, we also want to be mindful of our budgets and spend on technology as well. This is a great compromise and UX where we can reclaim unused license and if the human who lost their Photoshop license needs it again they can just request it again through our IT Help Desk system, and we can auto provision them another license. This way users can get the tech they need, and we can save money when it is not needed.
Until Next Time
Tools like osquery are not always straight forward to use and get returns off of. The Snowflake Data Platform really solves a big problem with getting the biggest returns from your osquery data. FleetDM makes managing osquery a breeze and my experiences with them have been great. Data modeling isn’t some mystic art and IT/Ops shops should really start thinking their data strategy if they don’t already have one. This type of data is paradigm shifting, and words really cannot describe how great it is.